- وام های تصمیم فوری.
- کشف قیمت
- محدودیت درآمد ماهانه اداره پست به 9 روپیه برای افراد در بودجه اتحادیه 2023 افزایش یافته است
- نمودارها نشان می دهند که بیت کوین در حال آماده شدن برای شکست است
- یک کارگزار وام مسکن چه کاری انجام می دهد؟
- 7 استراتژی مفید در معاملات فارکس
- تجمع بیت کوین چیزی بیش از یک گزاف گویی است - صعودی کنید
- سوالات متداول
- فرمول تجزیه و تحلیل نقطه ای یکنواخت
- استراتژی های معاملات 20 روزه برای مبتدیان و متخصصان

آخرین مطالب
امکانات وب


این کتاب در بازبینی باز است. ما از نظرات شما می خواهیم تا کتاب را برای شما و سایر دانش آموزان بهتر کند. می توانید با انتخاب آن با مکان نما، متنی را حاشیه نویسی کنید و سپس روی منوی بازشو کلیک کنید. همچنین می توانید حاشیه نویسی های دیگران را مشاهده کنید: در گوشه سمت راست بالای صفحه کلیک کنید
14. 7 غیر ایستایی I: روندها
اگر یک سری غیر ثابت باشد، آزمون های فرضیه های مرسوم، فواصل اطمینان و پیش بینی ها می توانند به شدت گمراه کننده باشند. اگر یک سری روندها یا شکستگی ها را نشان دهد و عوارض ناشی از آن در تحلیل اقتصادسنجی به نوع خاصی از ناپایداری بستگی داشته باشد، فرض ثابت بودن نقض می شود. این بخش بر سری های زمانی که روندها را نشان می دهند تمرکز دارد.
به یک سری گفته می شود که اگر حرکت طولانی مدتی داشته باشد، روندی را نشان می دهد. می توان بین روندهای قطعی و تصادفی تمایز قائل شد.
- اگر یک روند یک تابع غیرتصادفی از زمان باشد قطعی است.
- اگر یک روند یک تابع تصادفی از زمان باشد، به صورت تصادفی گفته می شود.
ارقامی که ما در فصل 14. 2 تهیه کرده ایم نشان می دهد که بسیاری از سری های زمانی اقتصادی یک رفتار روندی را نشان می دهند که احتمالاً بهترین مدل سازی با روندهای تصادفی است. به همین دلیل است که کتاب بر روی درمان روندهای تصادفی تمرکز دارد.
مدل پیاده روی تصادفی یک روند
ساده ترین راه برای مدل سازی سری زمانی (Y_t) که روند تصادفی دارد، پیاده روی تصادفی [x08egin Y_t = Y_ + u_t، ag end] است که در آن (u_t) i. d است. خطاهای (E(u_tvert Y_، Y_، dots) = 0). توجه داشته باشید که [شروع E(Y_tvert Y_, Y_dots) =& , E(Y_vert Y_, Y_dots) + E(u_tvert Y_, Y_dots) \ =& , Y_ end] بنابراین بهترین پیش بینی برای (Y_t) مشاهده دیروز (Y_) است. بنابراین تفاوت بین (Y_t) و (Y_) غیر قابل پیش بینی است. مسیری که (Y_t) دنبال می شود از مراحل تصادفی (u_t) تشکیل شده است، از این رو به آن راه رفتن تصادفی می گویند.
فرض کنید (Y_0) ، مقدار شروع پیاده روی تصادفی (0) است. روش دیگر برای نوشتن (14. 6) [شروع Y_0 =& , 0 \ Y_1 =& , 0 + u_1 \ Y_2 =& , 0 + u_1 + u_2 \ vdots & , \ Y_t=& ، sum_^t u_i.end] بنابراین ما [x08egin Var(Y_t) =& , Var(u_1 + u_2 + dots + u_t) \ =& , t sigma_u^2 داریم.end] بنابراین واریانس یک راه رفتن تصادفی به (t) بستگی دارد که فرض ارائه شده در مفهوم کلیدی 14. 5 را نقض می کند: یک راه رفتن تصادفی غیر ثابت است.
شبیه سازی پیاده روی تصادفی در داخل آسان استRاستفاده كردنarima. sim(). کارکردmatplot()برای نمودارهای ساده از ستون های یک ماتریس مناسب است.
# پیاده روی های تصادفی را شبیه سازی و ترسیم کنید از 0 set. seed(1) RWSts(تکثیر(n = 4, arima. sim(مدل = لیست(سفارش = c(0, 1 ,0)), n = 100))) منگوله(RWS ، نوع = "ل", col = c("SteelBlue", "سبز تیره", "قرمز تیره", "نارنجی"), lty = 1, LWD = 2, اصلی = "چهار پیاده روی تصادفی", xlab = "زمان", ylab = "ارزش")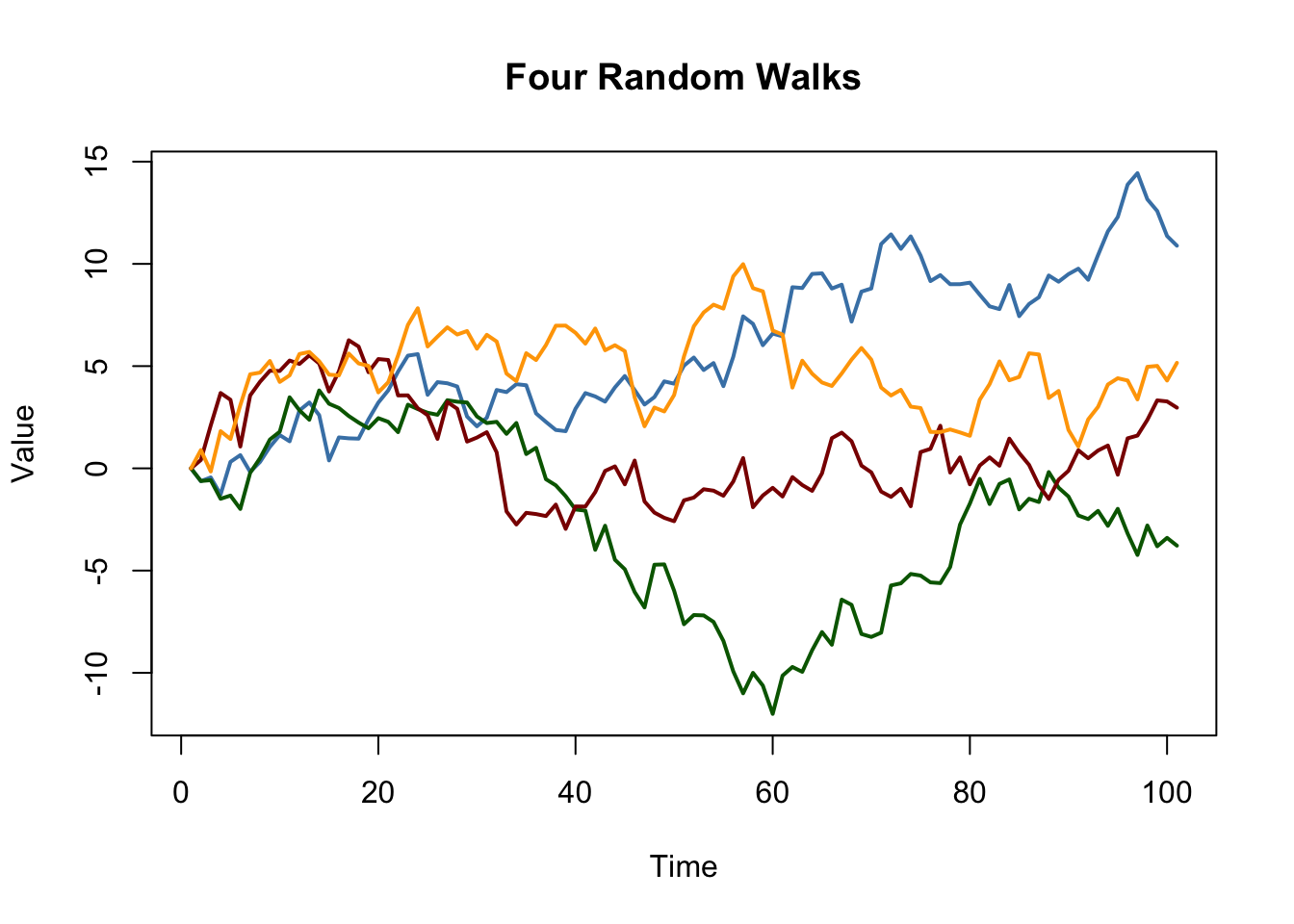
اضافه کردن یک ثابت به (14. 6) بازده [ شروع y_t = beta_0 + y_ + u_t tag ، end ] یک مدل پیاده روی تصادفی با یک رانش که امکان مدل سازی تمایل یک سری را به سمت بالا یا پایین می دهد. اگر ( beta_0 ) مثبت باشد ، این سریال به سمت بالا می رود و اگر ( beta_0 ) منفی باشد ، روند نزولی را دنبال می کند.
# پیاده روی های تصادفی را با رانش شبیه سازی و ترسیم کنید set. seed(1) RWSDts(تکثیر(n = 4, arima. sim(مدل = لیست(سفارش = c(0, 1, 0)), n = 100, میانگین = -0. 2))) منگوله(RWSD ، نوع = "ل", col = c("SteelBlue", "سبز تیره", "قرمز تیره", "نارنجی"), lty = 1, LWD = 2, اصلی = "چهار پیاده روی تصادفی با رانش", xlab = "زمان", ylab = "ارزش")
مشکلات ناشی از روندهای تصادفی
برآورد OLS از ضرایب بر روی رگرسیون که روند تصادفی دارند مشکل ساز است زیرا توزیع برآوردگر و (t ) آن غیر طبیعی است ، حتی بدون علامت. این عواقب مختلفی دارد:
- تعصب رو به پایین از ضرایب اتورگرایی: اگر (y_t ) یک پیاده روی تصادفی است ، ( beta_1 ) می تواند به طور مداوم توسط OLS تخمین زده شود اما برآوردگر نسبت به صفر مغرضانه است. این تعصب تقریباً (e ( widehat_1) تقریبا 1 - 5. 3/t ) است که برای اندازه های نمونه که به طور معمول در اقتصاد کلان مشاهده می شود ، قابل توجه است. این تعصب تخمین باعث می شود پیش بینی (y_t ) بدتر از یک مدل پیاده روی تصادفی خالص باشد.
- توزیع غیر عادی (t ) -Statistic: توزیع غیر طبیعی ضریب تخمین زده شده یک رگرسور تصادفی به توزیع غیر طبیعی از (t ) -statistic آن ترجمه می شود به طوری که مقادیر بحرانی طبیعی نامعتبر و بنابراین فواصل اعتماد به نفس معمول و در نتیجه معمول اعتماد به نفس هستندآزمون های فرضیه نیز نامعتبر هستند ، و توزیع واقعی (t ) -statistic نمی تواند به راحتی مشخص شود.
- رگرسیون فریبنده: هنگامی که دو سری زمانی به صورت تصادفی روند بر روی یکدیگر قرار می گیرند ، ممکن است رابطه تخمین زده شده با استفاده از مقادیر بحرانی معمولی معمولی بسیار معنی دار به نظر برسد ، اگرچه این سری ارتباط ندارد. این همان چیزی است که اقتصاددانان رابطه ای فریبنده می نامند.
به عنوان نمونه ای برای رگرسیون فریبنده ، پیاده روی های تصادفی سبز و قرمز را که در بالا شبیه سازی کرده ایم ، دوباره در نظر بگیرید. ما می دانیم که هیچ ارتباطی بین هر دو سری وجود ندارد: آنها به طور مستقل از یکدیگر تولید می شوند.
# رابطه توهین آمیز منگوله(RWS [،c(2, 3)], lty = 1, LWD = 2, نوع = "ل", col = c("سبز تیره", "قرمز تیره"), xlab = "زمان", ylab = "", اصلی = "یک رابطه جعلی") 
تصور کنید ما این اطلاعات را نداشتیم و در عوض حدس زدیم که سری سبز برای پیش بینی سری قرمز مفید است و در نتیجه به تخمین مدل ADL( (0) , (1) ) [x08egin Red_t = x08eta_0 ختم می شود.+ x08eta_1 سبز_ + u_t.پایان]
# تخمین مدل AR جعلی خلاصه(dynlm(RWS [،2] ~ L(RWS [،3])))$ضرایب #> Estimate Std. Error t value Pr(>|t|) #>(رهگیری) -3. 459488 0. 363510 4-9. 516889 1. 354156e-15 #>L(RWs[, 3]) 1. 047195 0. 1450874 7. 217687 1. 135828e-10نتیجه آشکارا جعلی است: ضریب (Green_) حدود (1) و (p) -مقدار (1. 14 cdot 10^) از (t) مربوطه تخمین زده می شود.) -تست نشان می دهد که ضریب بسیار معنی دار است در حالی که مقدار واقعی آن در واقع صفر است.
به عنوان یک مثال تجربی، نرخ بیکاری ایالات متحده و تولید صنعتی ژاپن را در نظر بگیرید. هر دو سری از اواسط دهه 1960 تا اوایل دهه 1980 روند صعودی را نشان می دهند.
# طرح نرخ بیکاری ایالات متحده و تولید صنعتی ژاپن طرح(ادغام(as. zoo(USUnemp)،as. zoo(JPIndProd))، plot. type = "تنها", col = c("قرمز تیره", "SteelBlue"), LWD = 2, xlab = "تاریخ", ylab = "", اصلی = "رگرسیون جعلی: سری زمانی کلان اقتصادی") # افسانه اضافه کنید افسانه("بالا سمت چپ", افسانه = c("USUnemp", "JPIndProd"), col = c("قرمز تیره", "SteelBlue"), LWD = c(2, 2))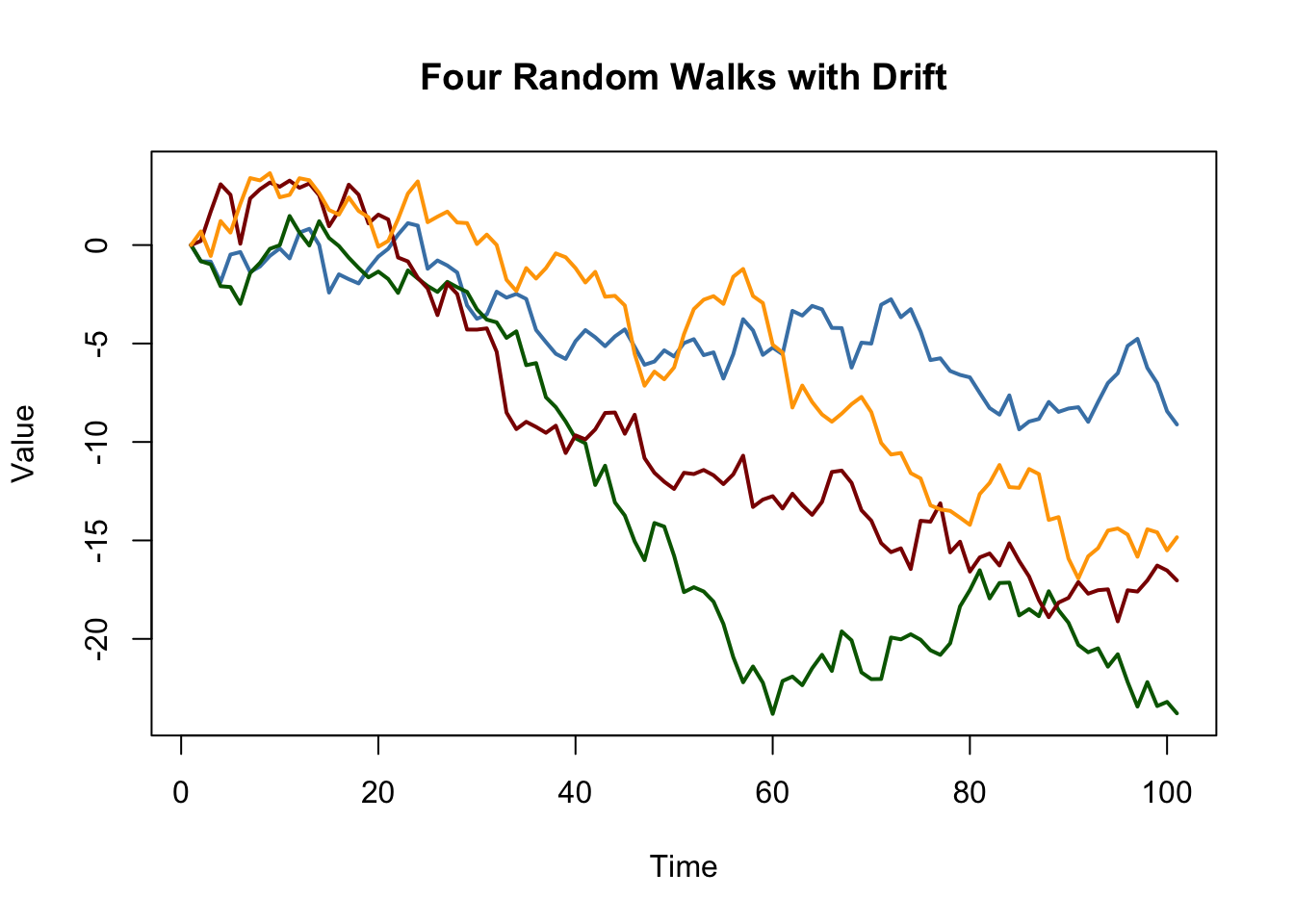
# تخمین رگرسیون با استفاده از داده های 1962 تا 1985 SR_Unemp1dynlm(ts(USUnemp["1962::1985"]) ~ ts(JPIndProd["1962::1985"])) coeftest(SR_Unemp1،vcov =ساندویچ) #> #>آزمون t ضرایب: #> #> Estimate Std. Error t value Pr(>|t|) #>(رهگیری) -2. 37452 1. 1204 1-2. 1193 0. 0367 * #>ts(JPIndProd["1962::1985"]) 2. 22057 0. 29233 7. 5961 2. 227e-11 *** #> --- #>Signif. کدها: 0 '***' 0. 001 '**' 0. 01 '*' 0. 05 '.'0. 1 "" 1یک رگرسیون ساده از نرخ بیکاری ایالات متحده در تولید صنعتی ژاپن با استفاده از داده های 1962 تا 1985، [x08egin widehat_t = -underset + underset log (JapaneseIP_t) را به دست می دهد. ag end] به نظر می رسد این یک رابطه معنی دار باشد: آماره (t) ضریب در (log(JapaneseIP_t)) بزرگتر از 7 است.
# تخمین رگرسیون با استفاده از داده های 1986 تا 2012 SR_Unemp2dynlm(ts(USUnemp["1986::2012"]) ~ ts(JPIndProd["1986::2012"])) coeftest(SR_Unemp2،vcov =ساندویچ) #> #>آزمون t ضرایب: #> #> Estimate Std. Error t value Pr(>|t|) #>(رهگیری) 41. 7763 5. 4066 7. 7270 6. 596e-12 *** #>ts(JPIndProd["1986::2012"]) -7. 7771 1. 171 4-6. 6391 1. 386e-09 *** #> --- #>Signif. کدها: 0 '***' 0. 001 '**' 0. 01 '*' 0. 05 '.'0. 1 "" 1هنگام برآورد همان مدل ، این بار با داده های 1986 تا 2012 ، ما [ شروع widehat_t = underet - underet log (ژاپنیپ) _t tag end ] را بدست می آوریم که با تعجب کاملاً متفاوت است.(14. 8) بر خلاف ضریب منفی بزرگ در (14. 9) رابطه مثبت متوسط را نشان می دهد. این پدیده را می توان به روندهای تصادفی در این سریال نسبت داد: از آنجا که هیچ استدلال اقتصادی وجود ندارد که هر دو روند را نشان دهد ، ممکن است هر دو رگرسیون جالب باشد.
آزمایش برای یک ریشه واحد AR
یک آزمایش رسمی برای یک روند تصادفی توسط دیکی و فولر (1979) ارائه شده است که بدین ترتیب آزمایش دیکی فولر نامیده می شود. همانطور که در بالا بحث شد ، یک سری زمانی که از یک مدل AR ( (1 )) با ( beta_1 = 1 ) پیروی می کند ، روند تصادفی دارد. بنابراین ، مشکل آزمایش [ شروع h_0: beta_1 = 1 h_1: lvert beta_1 rvert<1. end] The null hypothesis is that the AR( (1) ) model has a unit root and the alteative hypothesis is that it is stationary. One often rewrites the AR( (1) ) model by subtracting (Y_) on both sides: [x08egin Y_t = x08eta_0 + x08eta_1 Y_ + u_t Leftrightarrow Delta Y_t = x08eta_0 + delta Y_ + u_t ag end] where (delta = x08eta_1 - 1) . The testing problem then becomes [x08egin H_0: delta = 0 ext H_1: delta <0 end] which is convenient since the corresponding test statistic is reported by many relevant Rکارکرد. 11
آزمایش Dickey-Fuller همچنین می تواند در یک مدل AR ( (P )) اعمال شود. آزمون افزودنی Dickey-Fuller (ADF) در مفهوم کلیدی 14. 8 خلاصه شده است.
مفهوم کلیدی 14. 8
تست ADF برای یک ریشه واحد
رگرسیون را در نظر بگیرید [ delta y_t = beta_0 + delta y_ + gamma_1 delta_1 y_ + delta y_ + dots + gamma_p delta y_ + u_t. tag end ]
آزمون ADF برای یک واحد ریشه اتورگرایی واحد فرضیه (H_0: Delta = 0 ) (روند تصادفی) در برابر جایگزین یک طرفه (H_1: Delta<0) (stationarity) using the usual OLS (t) -statistic.
اگر فرض شود که (y_t ) در حدود یک روند خطی تعیین کننده ثابت است ، این مدل توسط رگرسور (t ) تقویت می شود: [ delta y_t = beta_0 + at + delta y_ + delta y_ + gamma_1 delta_1 y_ + gamma_2 delta y_ + gamma_p delta y_ + u_t ، tag end ] جایی که دوباره (h_0: delta = 0 ) در برابر (h_1: delta تست می شود.<0) .
طول تاخیر بهینه (P ) را می توان با استفاده از معیارهای اطلاعات تخمین زد. در (14. 11) ، (p = 0 ) (بدون تأخیر از ( delta y_t ) به عنوان رگرسیون استفاده می شود) با یک AR ساده ( (1 )) مطابقت دارد.
در زیر تهی ، (t ) -statistic مربوط به (h_0: delta = 0 ) توزیع عادی ندارد. مقادیر بحرانی فقط می تواند از شبیه سازی حاصل شود و برای رگرسیون (14. 11) و (14. 12) متفاوت است زیرا توزیع آمار آزمون ADF نسبت به اجزای قطعی موجود در رگرسیون حساس است.
مقادیر مهم برای آمار ADF
مفهوم کلیدی 14. 8 بیان می کند که مقادیر بحرانی برای آزمون ADF در رگرسیون (14. 11) و (14. 12) تنها با استفاده از شبیه سازی قابل تعیین هستند. ایده مطالعه شبیه سازی شبیه سازی تعداد زیادی از آمار آزمون ADF و استفاده از آنها برای تخمین چندک توزیع مجانبی آنهاست. این بخش نشان می دهد که چگونه می توان این کار را با استفاده از آن انجام دادR.
ابتدا مدل AR( (1)) زیر را با intercept [x08egin Y_t =& , alpha + z_t, \ z_t =
ho z_ + u_t در نظر بگیرید.end] این را می توان به صورت [x08egin Y_t =& , (1-
- ho) alpha +
- ho y_ + u_t, end] نوشت، یعنی (Y_t) یک راه رفتن تصادفی بدون رانش استزیر صفر (
- ho = 1) . می توان نشان داد که (Y_t) یک فرآیند ثابت با میانگین (alpha) برای (lvert
ho
vert است.
روش شبیه سازی مقادیر بحرانی یک آزمون ریشه واحد با استفاده از نسبت (t) - (delta) در (14. 10) به شرح زیر است: N 1000 شبیه سازی (N) پیاده روی تصادفی با مشاهدات (n) با استفاده از فرآیند تولید داده [x08egin Y_t =& , a + z_t, \ z_t = n 1000 ho z_ + u_t, end] (t=1،dots،n) که در آن (N) و (n) اعداد بزرگ هستند، (a) یک ثابت و (u) یک جمله خطای میانگین صفر است. برای هر پیاده روی تصادفی، رگرسیون [x08egin Delta Y_t =&, x08eta_0 + delta Y_ + u_t end] را تخمین زده و آمار آزمون ADF را محاسبه کنید. تمام آمار آزمایش (N) را ذخیره کنید.0.5 چندک های توزیع آمار آزمون ADF را با استفاده از آمار آزمون (N) به دست آمده از شبیه سازی تخمین بزنید.1:n برای حالت رانش و روند زمانی خطی، فرآیند تولید داده را با [x08egin Y_t =& , a + b cdot t + z_t, \ z_t = 1 ho z_ + u_t ag end] جایگزین می کنیم.(b cdot t) یک روند زمانی خطی است.(Y_t) در (14. 13) یک راه رفتن تصادفی با (بدون) دریفت است اگر (b eq0) ( (b=0) ) زیر تهی (ho=1) (می توانیداین را نشان دهید؟). ما رگرسیون [x08egin Delta Y_t =&, x08eta_0 + alpha cdot t + delta Y_ + u_t را تخمین می زنیم.پایان]به زبان ساده، دقت چندک های تخمین زده شده به دو عامل بستگی دارد: (n)، طول سری زیربنایی و (N) تعداد آمار آزمون استفاده شده. از آنجایی که ما علاقه مند به تخمین چندک های توزیع مجانبی (توزیع دیکی-فولر) آماره آزمون ADF هستیم، هم با استفاده از مشاهدات زیاد و هم تعداد زیاد آمار آزمون شبیه سازی شده، دقت چندک های برآورد شده را افزایش می دهد. ما (n=N=1000) را انتخاب می کنیم زیرا بار محاسباتی به سرعت با (n) و (N) افزایش می یابد.#تکرار# مشاهدات# ثابت، روند و rho را تعریف کنید رانشروندin 2:n) rho*# عملکردی که یک فرآیند AR (1) را شبیه سازی می کند-1] + AR1(1) > تابع(Rho) > خارج عددیts(تکثیر(n =برای+ (منبیرون [i] rho بیرون [من با توجه به# مشاهدات(خارج) رانشروندin 1:تکثیرn ، رانشAR1خلاصه( dynlm(adfdعددی1) ~ Lعددی1)))$برای2, 3] > (من NCOLts(تکثیر(n =برای+خلاصه+ (منبیرون [i] rho (RWD [، من] ، (RWD [، من] ،# مشاهدات(خارج) رانشروندin 1:تکثیرروندAR1خلاصه( dynlm(adfdعددی1) ~ Lعددی1) + برای(من )$برای2, 3] > (RWDT)) adfdt [i](خلاصهدنلمc(0.1, فرق, (RWDT [، من] ،)), 2) #>(RWDT [، من] ، #>روند (rwdt [، i])) adfdt [i](خلاصهگردc(0.1, فرق, (RWDT [، من] ،)), 2) #>(RWDT [، من] ، #>0. 0110 ٪ 5 ٪ 1 ٪
-2. 6 2-2. 8 3-3. 39
| # مقادیر برای رگرسیون ADF با رانش و روند تخمین بزنید | گرد | 5% | 1% |
|---|---|---|---|
| مقید | (ADFDT ، | 0. 05 | 0. 01 |
| 10 ٪ 5 ٪ 1 ٪ | -3. 1 1-3. 4 3-3. 97 | مقادیر تخمین زده شده نزدیک به مقادیر بحرانی نمونه بزرگ آمار آزمون ADF است که در جدول 14. 4 کتاب گزارش شده است. | جدول 14. 2: مقادیر بحرانی نمونه بزرگ آزمون ADF |
رگرسیون های قطعی
10 ٪
فقط رهگیری -2. 57(-2. 86-3. 43 رهگیری و روند زمان -6, -3. 12 3, -3. 41 c(0, 0.6), lty = 2, ylab = ما ممکن است از آمار آزمون شبیه سازی شده برای مقایسه گرافیکی چگالی طبیعی استاندارد و (برآورد) هر دو تراکم فولر دیکی استفاده کنیم., xlab = منحنی, اصلی = (ایکس)،, col = "قرمز تیره", LWD = 2) lty = ylab =("چگالی"xlab =LWD = 2, col = "سبز تیره") ylab =("چگالی"LWD =LWD = 2, col = تراکم) # افسانه اضافه کنید افسانه("بالا سمت چپ", c("سبز تیره", خط, تراکم), col = c("قرمز تیره", "سبز تیره", تراکم), lty = c(2, 1, 1), LWD = 2)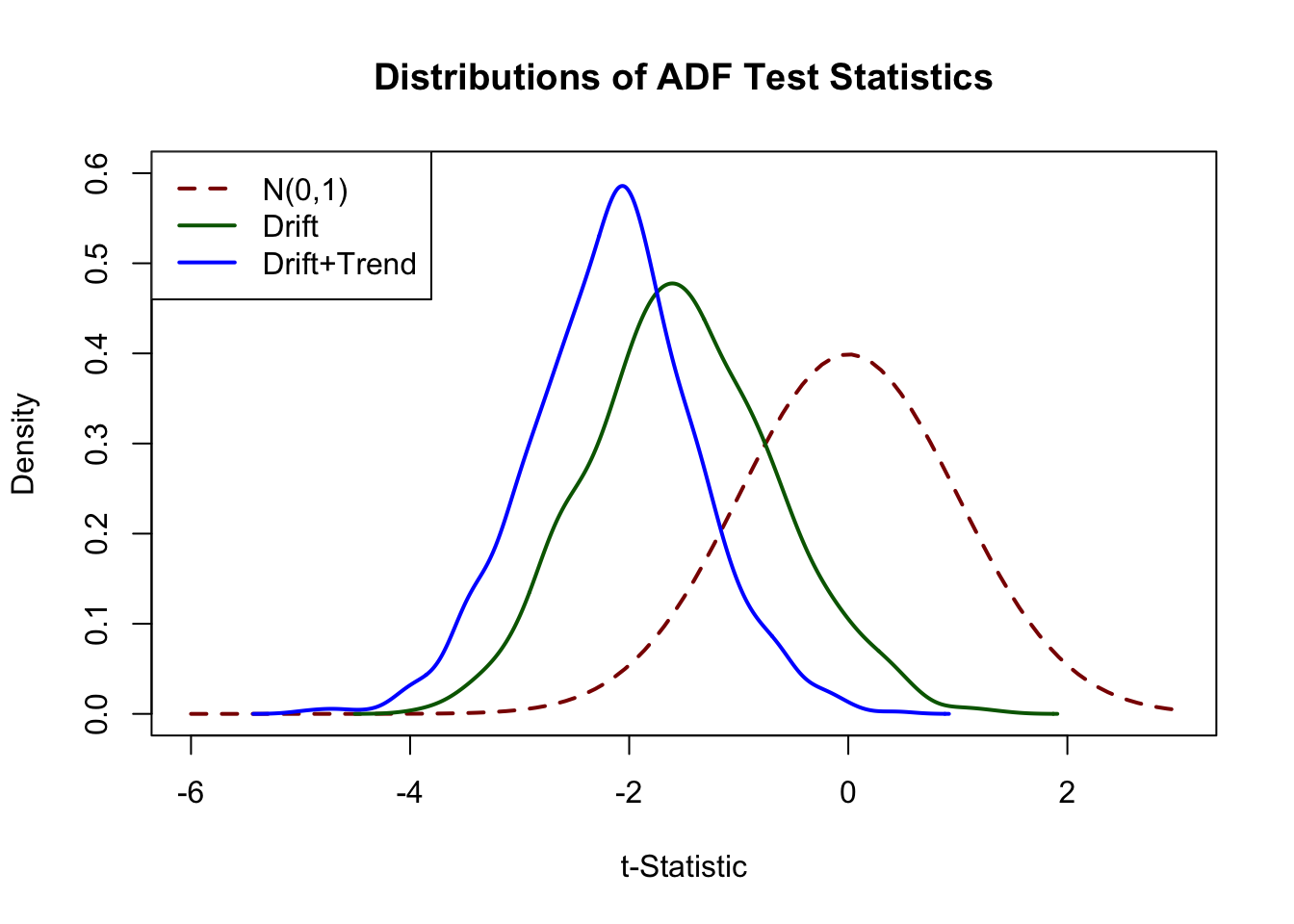
"بالا سمت چپ"
"n (0،1)"
"رانش"
"رانش+روند" col =ts("قرمز تیره""سبز تیره""آبی"])) lty = coeftest( dynlm(adfdبه عنوان یک نمونه تجربی ، ما از آزمون ADF برای ارزیابی اینکه آیا روند تصادفی در تولید ناخالص داخلی ایالات متحده با استفاده از رگرسیون وجود دارد ، استفاده می کنیم.+ beta_2 delta log (gdp_) + beta_3 delta log (gdp_) + u_t.پایان]~ برایلگدورود به سیستم(تولید ناخالص ملی[+ L"1962 :: 2012" + adfd(Lباسن+ adfd(Lفرق2))) #> #>آزمون t ضرایب: #> #> Estimate Std. Error t value Pr(>|t|) #>(loggdp ، #>مقیاس = #>f) #>(loggdp) #>فرق #> --- #>Signif. کدها: 0 '***' 0. 001 '**' 0. 01 '*' 0. 05 '.'0. 1 "" 1فرق
(loggdp) ،تست ضرایب:| T |)(رهگیری) 0. 27877045 0. 11793233 2. 3638 0. 019066 *.
روند (LogGDP ، مقیاس = F) 0. 00023818 0. 00011090 2. 1476 0. 032970 * خلاصه(Diff (L (LogGDP)) 0. 08317976 0. 11295542 0. 7364 0. 462371Diff (L (logGDP) ، 2) 0. 18763384 0. 07055574 2. 6594 0. 008476 ** نوع = بازده تخمین [ start delta log (gdp_t) = & underet + underet t - underet log (gdp_) \ underet delta log (gdp_) + underet delta log(gdp_) + u_t ، end ] بنابراین آمار آزمون ADF (t = -0. 033/0. 014 = - 2. 35 ) است. مقدار بحرانی مربوطه (5 ٪ ) از جدول 14. 2 (-3. 41 ) است ، بنابراین ما نمی توانیم فرضیه تهی را رد کنیم که ( log (تولید ناخالص داخلی) ) یک روند تصادفی به نفع جایگزین آن داردثابت در یک روند زمان خطی قطعی., آزمایش ADF را می توان به راحتی با استفاده از آن انجام داد 2, ur. df () از بسته)) #> #> ############################################### #>عیاش #> ############################################### #> #># تست ریشه واحد در تولید ناخالص داخلی با استفاده از 'ur. df ()' از بسته 'urca' #> #> #>خلاصه #>ur. df~(loggdp ، #> #>نوع = #>"روند" #>تاخیر = #> #>selectlags = #> Estimate Std. Error t value Pr(>|t|) #># تست ریشه واحد تست دیکی-فولر افزوده # #>روند رگرسیون آزمون #>زنگ زدن: #>LM (فرمول = z. diff #>z. lag. 1 + 1 + tt + z. diff. lag) #> --- #>Signif. کدها: 0 '***' 0. 001 '**' 0. 01 '*' 0. 05 '.'0. 1 "" 1 #> #>حداقل 1Q میانه 3Q حداکثر #>-0. 02558 0-0. 004109 0. 000321 0. 004869 0. 032781 #>ضرایب: #> #> #>| T |) #> #>(رهگیری) 0. 2790086 0. 1180427 2. 364 0. 019076 * #>Z. LAG. 1-0. 0333245 0. 014414 4-2. 312 0. 021822 * #>TT 0. 0002382 0. 0001109 2. 148 0. 032970 * #>z. diff. lag1 0. 2708136 0. 0697696 3. 882 0. 000142 *** #>z. diff. lag2 0. 1876338 0. 0705557 2. 659 0. 008476 **علامت گذاریکدها: 0 '***' 0. 001 '**' 0. 01 '*' 0. 05 '.'0. 1 '' 1خطای استاندارد باقیمانده: 0. 007704 در 196 درجه آزادیMultiple R-Squared: 0. 1783 ، تنظیم R-Squared: 0. 1616
F-Statistic: 10. 63 در 4 و 196 df ، p-value: 8. 076e-08
مقدار آمار آزمون است: -2. 3119 11. 2558 4. 267
- مقادیر بحرانی برای آمار آزمون:

ما را در سایت مدرسه فارکس معامله گر ایرانی دنبال می کنید
برچسب :
نویسنده : صالح پور مهروز
بازدید : 26
